|
|
캐시를 이용한 성능 향상!
객체를 캐싱함으로써 객체 생성과 관련된 성능을 향상시킬 수 있다.
섹션 목록
캐싱(Caching)
성능을 향상시키기 위해서 많이 사용되는 방법을 말해보라고 하면 대부분 객체 풀링을 말한다. 특히 데이터베이스 커넥션 풀이나 쓰레드 풀과 같은 것들이 일반 개발자들에게 보편화되면서 객체 풀링은 성능 향상을 위해서 반드시 사용해야 하는 기술로서 여겨지기도 한다. 하지만, 객체 풀링 못지 않게 성능을 향상시킬 수 있는 방법이 있다. 바로 객체 캐싱이다. 객체 캐싱은 기존에 사용된 정보를 메모리에 저장해두었다가 다시 참조될 때 사용하는 기술로서 메모리 캐싱 기술과 그 근본 원리가 같다. 이번 글에서는 객체 캐싱을 구현하는 것에 대해 알아보며, 실제 테스트를 통해서 캐시를 사용했을 때와 사용하지 않았을 때의 성능상의 차이점을 알아볼 것이다. 또한, 객체 캐싱과 객체 풀링의 차이점에 대해서도 간단하게 살펴보도록 하겠다.
객체 캐싱
객체를 캐싱하는 기본 목적은 생성하는 데 (컴퓨터의 입장에서) 많은 시간이 소비되는 객체를 사용하고 난 뒤에 메모리에서 삭제하는 것이 아니라 메모리에 저장해두었다가 다시 그 객체가 사용될 때 메모리에서 바로 읽어옴으로써 객체를 생성하는 데 소비되는 시간을 줄이는 것에 있다.
예를 들어, 카탈로그에 있는 제품 정보를 보여주는 어플리케이션이 있다고 해 보자. 카탈로그에 있는 제품 정보를 보여주기 위해서는 데이터베이스에 연결해야 하며, SQL 문장을 실행해야 하고, SQL 문장의 실행 결과로부터 정보를 추출해서 알맞은 객체를 생성해야 한다. 즉, 누군가가 A 라는 제품 정보를 보길 원한다고 할 경우 '데이터베이스연결->SQL문장실행->정보추출->객체생성' 이라는 과정을 거쳐야 하며 또 누군가가 A 라는 제품 정보를 보길 원할 경우 다시 한번 이 과정을 거쳐야 한다. 이때, 일단 생성된 객체를 메모리에 저장한다고 해 보자. 이 경우 누군가가 메모리에 이미 저장되어 있는 제품 정보를 조회하고자 할 경우에는 '데이터베이스연결->SQL문장실행->정보추출->객체생성'이라는 과정을 거칠 필요 없이 메모리에 이미 저장되어 있는 객체를 사용한다면 엄청난 시간이 절약될 것이다. 이것이 바로 객체 캐싱의 기본 개념이다.
그림을 통해서 좀더 구체적으로 살펴보자. 그림1은 객체가 캐싱되는 과정을 그림으로 표현한 것이다. 여기서 [Content Manager] 객체는 요청한 컨텐츠 정보를 저장하고 있는 객체를 리턴해주는 역할을 맡고 있다고 가정한다.
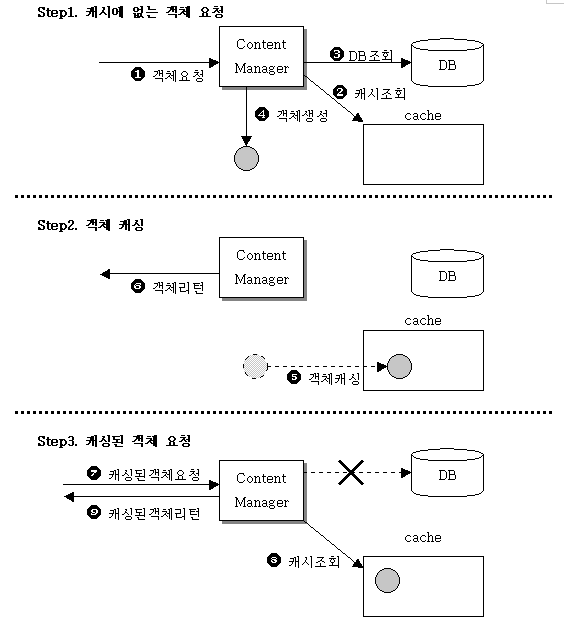
그림1 - 객체의 캐싱 과정
위 그림에서 1단계와 2단계를 살펴보자. [Content Manager]는 객체 생성 요청을 받을 경우(1) 먼저 캐시에 요청한 객체가 존재하는 지 확인한다.(2) 캐시에 요청한 객체가 존재하지 않는다면 객체 생성을 위해 필요한 정보를 추출한 후(3) 객체를 생성한다.(4) 그 다음에 생성한 객체를 캐시에 저장하고(5) 마지막으로 [Content Manager]는 생성한 객체를 리턴한다.(6)
일단 캐싱된 객체를 누군가가 요구할 경우, [Content Manager]는 그림1의 3단계 과정에서 볼 수 있듯이 캐시를 조회한 후 바로 캐시에 저장되어 있는 객체를 리턴해준다. 즉, 객체를 생성하기 위해 필요한 정보를 추출해내는 과정과 객체를 생성하는 과정이 생략되는 것을 알 수 있다. 이는 앞에서도 말했듯이 객체를 생성하는 데 소비되는 시간을 줄여주는 효과가 있다.
캐시 관리(Cache Management)
캐시와 관련해서 제한 사항이 있다면 그것은 바로 메모리의 크기가 무한하지 않다는 점에 있다. 모든 객체를 메모리에 저장하고 싶겠지만 메모리의 크기는 제한되어 있고 따라서 모든 객체를 메모리에 저장할 수는 없다. 또한 캐시로 사용하는 메모리의 크기가 너무 커서 실제 어플리케이션이 메모리를 사용하는 데 제한을 받으면 안 된다. 즉, 캐시로 사용할 메모리의 크기는 어플리케이션을 실행하는 데 영향을 주지 않을 정도로 작아야 한다.
객체를 캐싱하는 데 사용할 수 있는 메모리의 크기가 제한되어 있기 때문에 필요한 것이 바로 캐시에 저장할 객체를 선택하는 기준이다. 예를 들어, 고객들 대부분이 최신의 제품 정보를 보길 원한다고 해 보자. 이 경우 한 달 전에 캐시에 저장되어 있는 객체는 거의 사용되지 않을 것이며, 최근에 생성한 객체가 주로 사용될 것이다. 여기서 문제가 발생한다. 거의 사용되지 않는 객체가 캐시에 저장되어 있어서 최근 정보를 저장하고 있는 객체들이 더 이상 캐시에 저장될 수 없는 상황이 발생하는 것이다. 이는 모두 캐시로 사용될 메모리의 크기 제한에서 비롯된다.
그렇다면 이에 대한 해결방안은 무엇일까? 그것은 바로 잘 사용되지 않는 객체들은 캐시 메모리에서 삭제하고 주로 사용되는 객체를 캐시 메모리에 넣는 것이다. 이처럼 캐시에 참조될 가능성이 많은 객체들이 들어가도록 관리하는 것을 캐시 관리(Cache Management)라고 한다.
캐시를 관리하는 방법에는 여러 가지가 있으나, 일반적으로 많이 사용되는 방법은 LRU(Least Recently Used)이다. LRU는 가장 최근에 사용된 것을 캐시로 사용하는 메모리의 가장 앞쪽에 위치시키는 방법이다. 이를 알아보기 위해 다음 그림을 살펴보자.
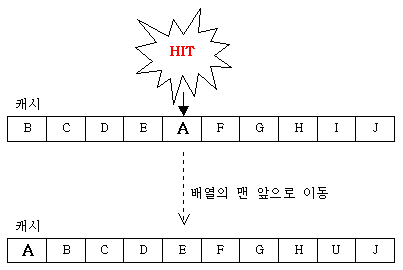
그림2 - LRU의 캐시 관리
위 그림은 캐시에 있는 A라는 객체를 누군가가 요청했을 때를 나타내는 것으로 그림1의 Step3의 과정8을 나타낸다. 누군가가 캐시에 이미 존재하고 있는 A 라는 객체를 요청할 경우 LRU 방식의 캐시에서는 위 그림과 같이 참조된 객체를 메모리의 가장 앞으로 보내며, 나머지 객체들은 뒤로 한칸씩 이동하게 된다. 캐시에 새로운 객체를 캐싱할 때는 메모리의 가장 앞에 넣는다. 이러한 과정에서 지속적으로 사용되는 객체는 항상 메모리의 앞쪽에 위치하게 되고, 그렇지 않은 객체는 자연적으로 메모리의 뒤쪽으로 이동하게 되며 결국에는 캐시에 삭제된다.
이렇게 자주 사용되는 객체를 앞쪽에 위치시키고 그렇지 않은 객체를 뒤쪽에 위치시키는 것은 캐시의 효율을 향상시키기 위한 것이다. 예를 들어, 게시판 데이터를 저장하고 있는 캐싱을 생각해보자. 사람들은 보통 게시판의 첫 페이지에 있는 글을 주로 읽으며 오래된 글은 좀처럼 읽지 않는다. 따라서 최신의 게시판 글을 저장하고 있는 객체를 캐시에 넣어둘 경우 그 만큼 시간에 대한 성능 향상이 발생하는 것이다. 실제로 가장 최근에 참조된 객체를 캐시에 지속적으로 저장하는 방식이 얼마나 효과적인지에 대해서는 테스트를 통해서 수치적으로 살펴볼 것이다.
객체 캐싱의 구현
객체 캐싱을 구현하기 위해서는 캐시의 역할을 할 클래스가 필요하다. 이 클래스는 내부적으로 객체를 저장할 공간을 갖고 있어야 하며 또한 LRU와 같은 방법을 사용하여 알맞게 캐시를 관리해야 한다. 여기서는 실제 예를 통해서 객체 캐싱을 구현해보자. 이 글에서 사용할 예는 컨텐츠와 관련된 것이며, 다음은 예제에서 사용되는 각 클래스들의 관계를 UML로 표시한 것이다.
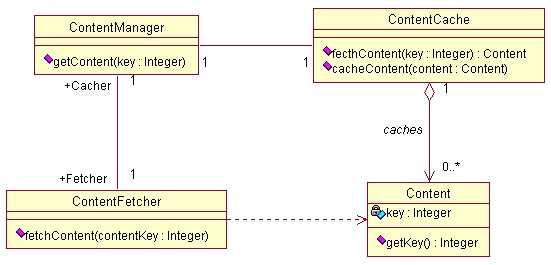
그림3 - 예제에서 사용되는 클래스간의 관계
그림3에서 클라이언트는 ContentManager 클래스를 통해서 Content 객체에 접근하게 된다. ContentCache 클래스는 Content 클래스의 객체를 캐싱하는 역할을 맡고 있으며 ContentFetcher는 DB로부터 정보를 읽어와 Content 객체를 생성하는 역할을 한다. Content 객체를 캐싱하는 과정은 다음 그림과 같다.
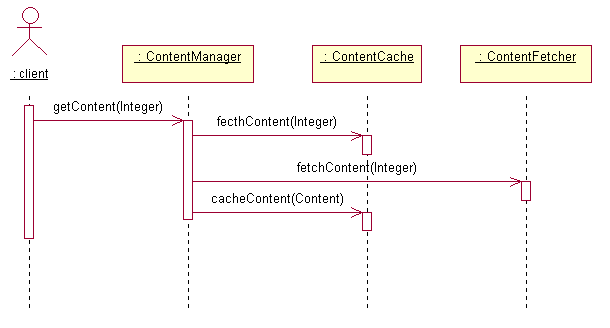
그림4 - 캐싱 과정
위 그림에서 클라이언트(임의의 모든 객체가 클라이언트가 될 수 있다)는 ContentManager의 getContent() 메소드를 호출하여 Content 객체를 구하게 된다. 이때 getContent() 메소드에 파라미터로 전달되는 Integer 객체는 각각의 Content를 구분할 때 사용되는 키(key)값이다. ContentManager의 getContent() 메소드는 ContentCache.fetchContent() 메소드를 사용하여 필요한 객체가 캐싱되어 있는 지 확인한다. ContentCache.fetchContent() 메소드는 요청한 객체가 캐싱되어 있지 않을 경우 null을 리턴하고, 캐싱되어 있을 경우 캐싱되어 있는 객체를 리턴한다. ContentCache.getchContent() 메소드가 null을 리턴할 경우 ContentManager는 ContentFetcher.fetchContent()를 사용하여 필요한 객체를 읽어오고 그 객체를 ContentCache.cacheContent()를 사용하여 캐싱한 후 클라이언트에 리턴해준다.
실제로 예제에서 사용되는 ContentManager의 getContent() 메소드는 다음과 같다.
public Content getContent(Integer contentKey) throws ContentFetcherException {
if (useCache) {
Content content = cache.fetchContent(contentKey);
// 캐시 검사
if (content == null) { // 캐시에 존재하지 않을 경우 ContentFetcher로부터 Content 객체 읽어온 후에 캐싱한다.
content = fetcher.fetchContent(contentKey);
cache.cacheContent(content);
}
return content;
} else {
return fetcher.fetchContent(contentKey);
}
}
여기서 useCache는 캐시를 사용할지의 여부를 나타내는 값이다.
ContentCache 클래스의 소스 코드
객체 캐싱에서 가장 핵심이 되는 부분은 역시 ContentCache 클래스이다. 먼저 ContentCache 클래스의 완전한 소스 코드부터 살펴보도록 하자.
package com.javacan.content;
import java.util.HashMap;
import java.util.ArrayList;
public class ContentCache {
public static final int DEFAULT_CACHE_SIZE = 30;
private HashMap keyMap;
private ArrayList cacheList;
private int cacheSize;
private int totalCount; // 전체 fetchContent 호출 회수
private int hitCount; // hit 회수
public ContentCache(int cacheSize) {
keyMap = new HashMap();
cacheList = new ArrayList(cacheSize);
this.cacheSize = cacheSize;
}
public Content fetchContent(Integer contentKey) {
totalCount ++;
Content content = (Content)keyMap.get(contentKey); // 지정한 컨텐츠가 없을 경우 null을 리턴
if (content != null) { // LRU에 따라 가장 앞으로 이동 hitCount ++; cacheList.remove(content);
cacheList.add(0, content);
}
return content;
}
public void cacheContent(Content content) { // 새로운 Content와 같은 키값을 갖는 content가 존재하는 지 확인
Content oldContent = (Content)keyMap.get(content.getKey());
if (oldContent != null) { // 존재한다면 기존 캐시 리스트 에서 content를 삭제한다.
cacheList.remove(oldContent);
} else { // 존재하지 않는다면 현재 캐시의 크기가 지정한 크기와 같은 지 검사한다. 그래서 같다면 가장 cacheList의 가장 // 마지막에 있는 걸 삭제한다.
if (cacheSize == cacheList.size()) {
Content lastContent = (Content)cacheList.remove(cacheSize-1); keyMap.remove(lastContent.getKey()); } } // 가장 처음에 삽입한다. keyMap.put(content.getKey(), content); cacheList.add(0, content); } public double getHitRate() { return (double)hitCount / (double)totalCount; } public int getCacheSize() { return cacheSize; } }
위 코드에서 실제 캐싱을 위한 메모리 역할을 하는 것은 ArrayList인 cacheList이다. fetchContent() 메소드와 cacheContent() 메소드를 보면 cacheList에 저장된 객체의 순서를 LRU에 따라 알맞게 변경하는 것을 알 수 있다. 또한 히트율(hit rate)을 구하기 위해 fetchContent() 메소드가 호출된 회수와 히트 회수를 각각 totalCount 필드와 hitCount 필드에 기록한다. HashMap인 keyMap을 사용한 이유는 캐시에 객체가 저장되어 있는지의 여부를 좀더 빠르게 검색하기 위해서이다. 코드 자체는 크게 복잡하지 않으므로 자세한 설명은 하지 않겠다.
ContentCache 이외의 다른 코드는 관련 링크의 소스 코드를 참고하기 바란다. ContentFetcher 클래스는 실제로 데이터베이스와 연동되기 때문에 여러분이 직접 테스트하기 위해서는 알맞게 변경해야 한다.
캐싱의 성능 테스트
이 글에서는 먼저 테스트를 위해 다음과 같은 테이블을 생성하였으며, ContentFetcher.fetchContent() 메소드는 이 테이블로부터 정보를 읽어오도록 구현하였다.
|
테이블명: CONTENT | |
|
컬럼 |
Oracle 타입 |
|
SNUMBER |
NUMBER(38) |
|
REGDATE |
DATE |
|
TITLE |
VARCHAR2(100) |
|
CONTENT |
VARCHAR2(2000) |
테스트를 위한 데이터를 100개 삽입하였으며 이 100개의 데이터의 SNUMBER는 1부터 100이 되도록 하였다. 여기서는 다음과 같은 조건으로 테스트를 하였다.
- 캐시를 사용하는 상태에서 데이터를 1000번 조회하는 데 걸리는 시간을 기록한다.
- 캐시를 사용하지 않는 상태에서 데이터를 1000번 조회하는 데 걸리는 시간을 기록한다.
- 1과 2를 각각 10번씩 반복한다. (즉, 전체적으로 10000번 조회하는 결과가 된다.)
- 캐시 크기를 20, 30, 40, 50 으로 변경하면서 1-3을 테스트한다.
- 데이터를 조회할 때에는 인접한 번호를 선택하도록 한다.
여기서 5번은 전에 조회한 번호와 비교하여 +/- 10 이내에 있는 내용을 조회한다는 것을 의미한다. 즉, 현재 조회한 번호가 17일 경우 다음에는 7부터 27 사이에 있는 데이터를 조회한다는 것을 의미한다. 이렇게 함으로써 인접한 데이터를 선택하도록 하였고 이를 통해 LRU를 적용한 캐시가 얼마나 효율적인지 테스트해보았다. 테스트 코드는 소스 코드에 함께 첨부되어 있으니 살펴보기 바란다.
가장 먼저 살펴볼 테스트 결과는 데이터를 1000번 조회하는 데 걸린 시간이다. 1000번씩 연속적으로 10번을 조회하는데 걸린 시간의 변화추이를 그림5에 표시하였다.
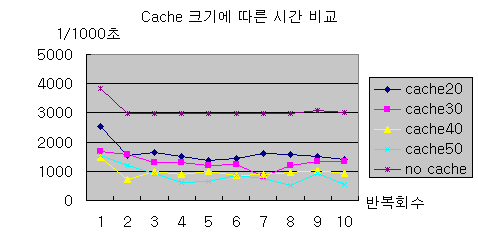
그림5 - 캐시 크기에 따른 시간 비교
그림5의 결과에서 첫번째 특징은 캐시의 크기가 커질수록 1000번을 조회하는 데 적은 시간이 걸린다는 점이다. 특이한 점은 모든 경우에 있어서 처음 천번을 조회할 때 걸리는 시간이 상대적으로 길다는 점이다. 이는 데이터베이스에서 SQL 쿼리 결과를 캐싱하는 것과도 관련이 있는 것으로 보인다. 즉, 첫번째 이후부터는 데이터베이스에 캐싱되어 있는 결과를 읽어올 가능성이 커지기 때문에 전체적으로 첫번째 1000번에 비해서 상대적으로 적은 시간이 걸리는 것이다.
위 결과에서 또 다른 특징은 캐시를 사용하지 않는 경우 2번째부터 10번째까지의 처리 시간이 매우 일정한 반면에 캐시를 사용하는 경우 걸리는 시간이 일정 범위 내에서 가변적인 것을 알 수 있다. 또한, 어떤 경우에는 캐시 크기가 작을 때 오히려 시간이 더 적게 걸리는 경우도 있는 것을 알 수 있다. 이처럼 캐시를 사용할 때 처리하는 시간이 일정하지 않은 것은 랜덤하게 데이터를 읽어왔기 때문이다. 비록 인접한 번호를 읽어온다고 하지만 랜덤한 번호를 읽어오는 것이기 때문에 캐시에 저장되는 객체의 참조 가능성도 그만큼 랜덤해지는 것이다.
위의 테스트 결과에서 첫 번째 1000번을 조회하는 데 걸린 시간을 제외한 나머지 2-10의 시간의 평균을 내보면 다음 그림6과 같다.
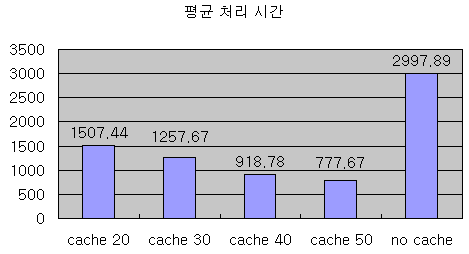
그림6 - 평균적인 처리 시간
그림6을 보면 확실하게 캐시의 크기가 커질수록 처리 시간이 작아진다는 것을 알 수 있다. 이는 곧 인접한 데이터를 조회할 경우, 캐시의 크기가 커질수록 캐시에 있는 데이터를 읽어올 가능성이 커진다는 것을 의미한다. 이는 실제로 캐시의 크기가 커질수록 히트율이 높아진다는 것을 의미하는데 그림7은 캐시의 크기와 히트율이 어떤 상관관계를 갖는지 보여주고 있다.
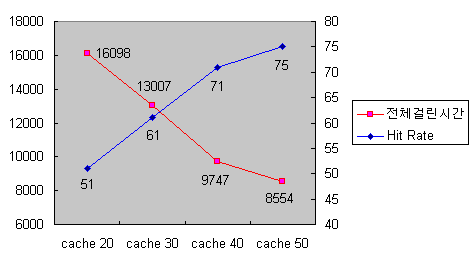
그림7 - 캐시 크기에 따른 전체 걸린 시간과 히트율
그림7을 보면 캐시의 크기가 커질수록 히트율이 증가하는 것을 알 수 있다. 그림7에서 눈여겨 볼 점이 있다면 캐시 크기를 40에서 50으로 늘릴 경우 히트율의 증가 추세가 캐시 크기를 20에서 30으로 또는 30에서 40으로 늘릴 경우에 비해 작다는 점이다. 이는 캐시 크기의 크기에 비례하여 히트율이 증가하지는 않는다는 것을 보여주는 것이다. 실제로 알맞은 캐시 크기는 어플리케이션에 따라서 달라지며 적정 수준에서 캐시 크기를 지정하는 것이 좋다.